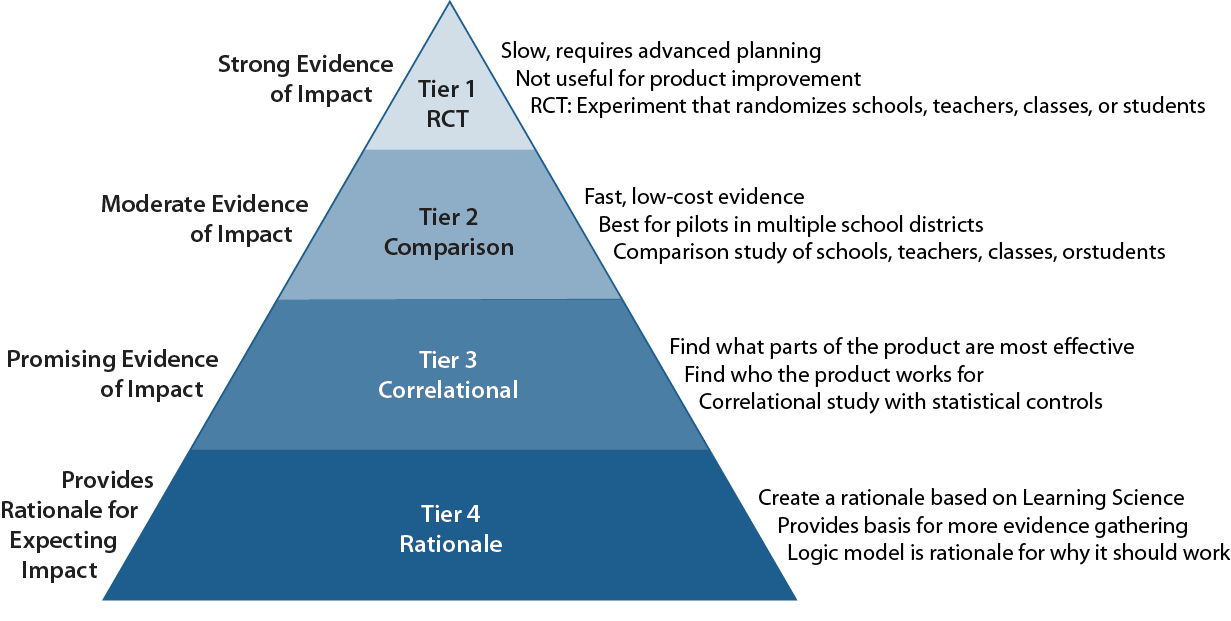
We and our colleagues have been working on translating the results of rigorous studies of the impact of educational products, programs, and policies for people in school districts who are making the decisions whether to purchase or even just try out—pilot—the product. We are influenced by Stanford University Methodologist Lee Cronbach, especially his seminal book (1982) and article (1975) where he concludes “When we give proper weight to local conditions, any generalization is a working hypothesis, not a conclusion…positive results obtained with a new procedure for early education in one community warrant another community trying it. But instead of trusting that those results generalize, the next community needs its own local evaluation” (p. 125). In other words, we consider even the best designed experiment to be like a case study, as much about the local and moderating role of context, as about the treatment when interpreting the causal effect of the program.
Following the focus on context, we can consider characteristics of the people and of the institution where the experiment was conducted to be co-causes of the result that deserve full attention—even though, technically, only the treatment, which was randomly assigned was controlled. Here we argue that any generalization from a rigorous study, where the question is whether the product is likely to be worth trying in a new district, must consider the full context of the study.
Technically, in the language of evaluation research, these differences in who or where the product or “treatment” works are called “interaction effects” between the treatment and the characteristic of interest (e.g., subgroups of students by demographic category or achievement level, teachers with different skills, or bandwidth available in the building). The characteristic of interest can be called a “moderator”, since it changes, or moderates, the impact of the treatment. An interaction reveals if there is differential impact and whether a group with a particular characteristic is advantaged, disadvantaged, or unaffected by the product.
The rules set out by The Department of Education’s What Works Clearinghouse (WWC) focus on the validity of the experimental conclusion: Did the program work on average compared to a control group? Whether it works better for poor kids than for middle class kids, works better for uncertified teachers versus veteran teachers, increases or closes a gap between English learners and those who are proficient, are not part of the information provided in their reviews. But these differences are exactly what buyers need in order to understand whether the product is a good candidate for a population like theirs. If a program works substantially better for English proficient students than for English learners, and the purchasing school has largely the latter type of student, it is important that the school administrator know the context for the research and the result.
The accuracy of an experimental finding depends on it not being moderated by conditions. This is recognized with recent methods of generalization (Tipton, 2013) that essentially apply non-experimental adjustments to experimental results to make them more accurate and more relevant to specific local contexts.
Work by Jaciw (2016a, 2016b) takes this one step further.
First, he confirms the result that if the impact of the program is moderated, and if moderators are distributed differently between sites, then an experimental result from one site will yield a biased inference for another site. This would be the case, for example, if the impact of a program depends on individual socioeconomic status, and there is a difference between the study and inference sites in the proportion of individuals with low socioeconomic status. Conditions for this “external validity bias” are well understood, but the consequences are addressed much less often than the usual selection bias. Experiments can yield accurate results about the efficacy of a program for the sample studied, but that average may not apply either to a subgroup within the sample or to a population outside the study.
Second, he uses results from a multisite trial to show empirically that there is potential for significant bias when inferring experimental results from one subset of sites to other inference sites within the study; however, moderators can account for much of the variation in impact across sites. Average impact findings from experiments provide a summary of whether a program works, but leaves the consumer guessing about the boundary conditions for that effect—the limits beyond which the average effect ceases to apply. Cronbach was highly aware of this, titling a chapter in his 1982 book “The Limited Reach of Internal Validity”. Using terms like “unbiased” to describe impact findings from experiments is correct in a technical sense (i.e., the point estimate, on hypothetical repeated sampling, is centered on the true average effect for the sample studied), but it can impart an incorrect sense of the external validity of the result: that it applies beyond the instance of the study.
Implications of the work cited, are, first, that it is possible to unpack marginal impact estimates through subgroup and moderator analyses to arrive at more-accurate inferences for individuals. Second, that we should do so—why obscure differences by paying attention to only the grand mean impact estimate for the sample? And third, that we should be planful in deciding which subgroups to assess impacts for in the context of individual experiments.
Local decision-makers’ primary concern should be with whether a program will work with their specific population, and to ask for causal evidence that considers local conditions through the moderating role of student, teacher, and school attributes. Looking at finer differences in impact may elicit criticism that it introduces another type of uncertainty—specifically from random sampling error—which may be minimal with gross impacts and large samples, but influential when looking at differences in impact with more and smaller samples. This is a fair criticism, but differential effects may be less susceptible to random perturbations (low power) than assumed, especially if subgroups are identified at individual levels in the context of cluster randomized trials (e.g., individual student-level SES, as opposed to school average SES) (Bloom, 2005; Jaciw, Lin, & Ma, 2016).
References:
Bloom, H. S. (2005). Randomizing groups to evaluate place-based programs. In H. S. Bloom (Ed.), Learning more from social experiments. New York: Russell Sage Foundation.
Cronbach, L. J. (1975). Beyond the two disciplines of scientific psychology. American Psychologist, 116-127.
Cronbach, L. J. (1982). Designing evaluations of educational and social programs. San Francisco, CA: Jossey-Bass.
Jaciw, A. P. (2016). Applications of a within-study comparison approach for evaluating bias in generalized causal inferences from comparison group studies. Evaluation Review, (40)3, 241-276. Retrieved from https://journals.sagepub.com/doi/abs/10.1177/0193841X16664457
Jaciw, A. P. (2016). Assessing the accuracy of generalized inferences from comparison group studies using a within-study comparison approach: The methodology. Evaluation Review, (40)3, 199-240. Retrieved from https://journals.sagepub.com/doi/abs/10.1177/0193841x16664456
Jaciw, A., Lin, L., & Ma, B. (2016). An empirical study of design parameters for assessing differential impacts for students in group randomized trials. Evaluation Review. Retrieved from https://journals.sagepub.com/doi/10.1177/0193841X16659600
Tipton, E. (2013). Improving generalizations from experiments using propensity score subclassification: Assumptions, properties, and contexts. Journal of Educational and Behavioral Statistics, 38, 239-266.